



I. Introduction▲
SIMD est l'acronyme de Single Instruction Multiple Datas (une seule instruction, plusieurs données). Ceci recouvre en fait plusieurs jeux d'instructions qui ont été ajoutés aux microprocesseurs Intel et compatibles ces dernières années. Les instructions MMX ont été les premières de la série en permettant d'effectuer simultanément la même instruction sur plusieurs nombres entiers. Elles ont déjà été évoquées dans deux articles, ici et là. Nous allons maintenant étudier les instructions SIMD concernant les nombres réels. Il s'agit des instructions SSE et SSE2 chez Intel ainsi que 3DNow! chez AMD. Ces instructions sont prises en charge par l'assembleur intégré (basm) de Delphi 6 et de Kylix. Donc, il faut abandonner temporairement le Pascal pour l'assembleur afin de les utiliser.
Nous aurons recours à un exemple simple, le calcul du milieu de deux points dans l'espace. Chaque point dispose de trois coordonnées x, y et z et nous devons juste faire la moyenne des coordonnées une à une pour trouver le milieu :
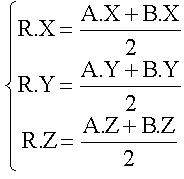
Ce qui se traduit en Pascal par :
type
TZPoint = record
X, Y, Z : Single;
end;
function MidPoint(const P1, P2: TZPoint): TZPoint;
const
Demi : single = 0.5;
begin
Result.X:= (P2.X+P1.X)*Demi;
Result.Y:= (P2.Y+P1.Y)*Demi;
Result.Z:= (P2.Z+P1.Z)*Demi;
end;Nous avons ici le code le plus optimisé possible en Pascal, en particulier la multiplication par 0,5 plutôt que la division par 2 permet de gagner beaucoup de temps. Le recours à une constante permet aussi d'améliorer le code généré. L'utilisation de l'assembleur classique en supprimant les FWAIT à la fin des lignes de calcul n'apporte pas de gain important. Que reste-t-il pour aller plus vite ? Les instructions SIMD! Nous allons commencer par le 3DNow !
II. 3DNow!▲
Ces instructions sont disponibles sur les microprocesseurs AMD depuis le K6-2. Il faut aller sur le site web d'AMD pour trouver la description des instructions. Les instructions 3DNow! utilisent les registres MMX. Il s'agit de registres 64 bits qui peuvent ainsi contenir chacun deux nombres réels simple précision. Et les instructions 3DNow! permettent ensuite de réaliser simultanément deux fois la même opération. En pratique, nous devons transférer nos données vers les registres MMX, effectuer les opérations, récupérer les données et désactiver les registres MMX. Comme je ne dispose de machine correspondante, Matthijs Laan a fait le travail de codage pour moi :
function MidPoint_3DNow(const P1, P2: TZPoint): TZPoint;
const
PackedHalf: packed array[0..1] of Single = (0.5, 0.5);
asm
movq mm0, [PackedHalf] // chargement de la constante précédente
movq mm1, [eax] // chargement de P1.X et P1.Y
pfadd mm1, [edx] // addition de P2.X et P2.Y
movd mm3, [eax + 8] // chargement de P1.Z
pfadd mm3, [edx + 8] // addition de P2.Z
pfmul mm1, mm0 // multiplication résultat sur X et Y par 0.5
pfmul mm3, mm0 // multiplication résultat sur Z par 0.5
movq [ecx], mm1 // déchargement de X et Y
movd [ecx + 8], mm3 // déchargement de Z
emms // désactivation de l'unité MMX
end;Le codage est aisé grâce à Delphi 6 qui reconnaît les instructions 3DNow ! Ça fonctionne et nous étudierons les performances à la fin de cet article en commun avec les autres jeux d'instructions.
III. SSE▲
Les instructions SSE sont apparues chez Intel avec le Pentium III puis ont été étendues au Celeron à partir du 533A. AMD les a portées sur ses microprocesseurs à partir de l'Athlon XP. Avec ces instructions, 8 nouveaux registres 128 bits ont été ajoutés au microprocesseur. Ils sont nommés de xmm0 à xmm7 et peuvent contenir 4 nombres réels simple précision. Nous pouvons ensuite réaliser quatre opérations simultanément. Néanmoins, Intel nous a réservé une mauvaise surprise en ne mettant, sur les PIII, qu'un bus 64 bits pour accéder aux registres xmm. Il faut donc deux instructions pour charger ou décharger un registre xmm :
movlps xmm0,[eax] //chargement de la partie basse de xmm0 avec P1
movhps xmm0,[eax+8] //chargement de la partie haute de xmm0 avec P1Ensuite, certaines instructions comme les opérations (addition, multiplication…) mettant en jeu un registre et une adresse mémoire exigent que cette adresse mémoire soit alignée sur 16 octets (=128 bits). Or le compilateur de Delphi aligne les données sur 4 octets (=32 bits) (Ref : Guide du langage Pascal Objet, Gestion de la mémoire). Première solution, ne pas utiliser les instructions à problème et trouver des méthodes de contournement. En termes de performances, c'est mauvais et mieux vaut ne pas utiliser les instructions SSE. Deuxième méthode, aligner les données sur 16 octets en remplaçant le gestionnaire de mémoire par défaut par le nôtre que nous avons pris soin de programmer dans cette optique. Pour ceux qui ne sont pas très familiers avec les gestionnaires de mémoire :-), Robert Lee a déjà fait le travail pour vous sous Delphi. Prenez son gestionnaire de mémoire et utilisez-le dans votre projet en l'appelant en premier :
program Project1;
uses
MultiMM, // ici, le nouveau gestionnaire de mémoire
Forms,
Unit1 in 'Unit1.pas' {Form1};Mais ce n'est pas suffisant, car le nouveau gestionnaire de mémoire n'aligne que les variables que vous allouez dynamiquement. Et pour allouer une variable, rien de tel que new :
T4DPoint = packed record // définition d'un format de 16 octets
X, Y, Z, T : Single;
end;
const
CPackedHalf: T4DPoint = (x:0.5; y:0.5; z:0.5; t:0.5); // constante de multiplication
var
Serie1bis, Serie2bis, Rapidebis, PackedHalf : ^T4DPoint;
begin
[...]
new(Serie1bis); // allocation dynamique des variables
new(Serie2bis);
new(Rapidebis);
new(PackedHalf); // allocation dynamique d'une variable pour la constante
PackedHalf^:=CPackedHalf; // transfert de la constante vers une variable alignée
[...]
MidPoint_SSE(Serie1bis^,Serie2bis^,Rapidebis^); // appel de la procédure de calcul
[...]
dispose(Serie1bis); // désallocation dynamique des variables
dispose(Serie2bis);
dispose(Rapidebis);
dispose(PackedHalf);
end;Nous pouvons enfin passer au calcul proprement dit :
procedure MidPoint_SSE(const P1, P2 : T4DPoint; var result : T4DPoint);
asm
movlps xmm0,[eax] // chargement de la partie basse de xmm0 avec P1
movhps xmm0,[eax+8] // chargement de la partie haute de xmm0 avec P1
mov eax,[PackedHalf] // récupération de l'adresse de la constante
addps xmm0,[edx] // addition de P2 à xmm0 (P1)
mulps xmm0,[eax] // multiplication du résultat par 0.5
movlps [ecx],xmm0 // déchargement de la partie basse de xmm0 avec P1
movhps [ecx+8],xmm0 // déchargement de la partie haute de xmm0 avec P1
end;Le calcul est simple, fonctionne et permet des gains de temps significatifs.
IV. SSE2▲
Les instructions SSE2 sont apparues avec le Pentium 4. Elles devraient être portées par AMD sur les Hammer (génération K8) à la mi-2003. Mais mon exemple fonctionne déjà sur les Athlon XP. Une partie des instructions SSE2 semble donc supportée par ce dernier. Outre l'introduction de nouvelles possibilités de calcul, elles correspondent à l'arrivée d'un bus 128 bits pour les registres xmm. Il devient donc possible de charger un registre xmm à l'aide d'une seule instruction, ce qui simplifie le code SSE sans changement par ailleurs :
procedure MidPoint_SSE2(const P1, P2 : T4DPoint; var result : T4DPoint);
asm
movaps xmm0,[eax]
mov eax,[PackedHalf]
addps xmm0,[edx]
mulps xmm0,[eax]
movaps [ecx],xmm0
end;Lorsque vous avez déjà écrit votre code SSE, le passage au SSE2 est très facile et consiste à simplifier le code. Il ne faut donc pas s'en priver.
V. Performances▲
Venons-en aux performances. J'ai mis dans le tableau suivant le temps moyen en nombre de cycles d'horloge pour calculer le milieu de deux points :
|
Architecture |
Proc / fréquence |
Pascal |
asm 1 (perso) |
asm 2 (Barry Kelly et al .) |
3DNow ! (Matthijs Laan et al.) |
SSE (perso) |
SSE2 (perso) |
Puissance effective / MFlops |
|---|---|---|---|---|---|---|---|---|
|
Intel P5 |
Pentium 90 |
38.5 |
35.5 |
32.6 |
X |
X |
X |
17 |
|
P 200 MMX |
51.2 |
51.2 |
63.3 |
X |
X |
X |
23 |
|
|
Intel P6 |
Celeron 333@375 |
18.0 |
16.8 |
16.7 |
X |
X |
X |
138 |
|
P III 500@560 |
18.1 |
17.0 |
17.1 |
X |
12.4 |
X |
270 |
|
|
P III 600 |
18.1 |
16.8 |
17.2 |
X |
12.3 |
X |
290 |
|
|
P III 633 |
18.2 |
17.0 |
17.0 |
X |
12.3 |
X |
310 |
|
|
P III 733 |
18.6 |
17.2 |
17.0 |
X |
12.1 |
X |
360 |
|
|
P III 1 GHz |
18.6 |
17.0 |
17.0 |
X |
12.1 |
X |
500 |
|
|
Intel P7 |
P4 1.5 |
19.8 |
16.0 |
18.2 |
X |
20.1 |
12.1 |
740 |
|
AMD K6 |
K6-2 333 |
52.3 |
45.6 |
60.7 |
22.3 |
X |
X |
90 |
|
AMD K7 |
Duron 800 |
12.0 12.5 |
15.0 12.1 |
13.0 13.0 |
10.4 10.1 |
X |
X |
460 480 |
|
Athlon 700 |
13.3 |
12.0 |
12.0 |
9.3 |
X |
X |
450 |
|
|
Athlon 1.0 |
14.8 |
12.0 |
15.0 |
10.0 |
X |
X |
600 |
|
|
Athlon 1.1 |
12.0 |
12.0 |
13.0 |
10.0 |
X |
X |
660 |
|
|
Athlon 1.35 |
12.1 |
12.0 |
13.0 |
10.0 |
X |
X |
810 |
|
|
Athlon XP 1600 + |
13.0 |
12.0 |
15.0 |
10.0 |
10.1 |
10.1 |
840 |
Pour les microprocesseurs de la famille Intel P6 avec instructions SSE, le gain est de 30 % en temps d'exécution, ce qui peut justifier le recours aux instructions SSE. Avec un Pentium 4, les instructions SSE sont pénalisantes et seul le recours au SSE2 permet un gain de 40 %. Vu comme ça, le SSE2 ressemble à une arnaque qui rend obsolète le code SSE écrit pour les PIII et vous oblige à passer au SSE2 pour rattraper les anciennes performances.
Un tour chez AMD montre d'abord que le 3DNow! est très performant avec les K6 (gain 57 %). À l'opposé, avec la nouvelle architecture (Athlon et Duron), les gains sont faibles et l'opportunité d'écrire un code spécial 3DNow! se pose.
Enfin, la comparaison entre Intel et AMD est toute à l'avantage de ce dernier avec un code en Pascal aussi performant que celui optimisé SSE/SSE2 chez Intel. Ce constat est d'ailleurs confirmé par pas mal de tests sur Internet. Il ne faut toutefois pas perdre de vue que nous avons travaillé ici sur un exemple un peu fictif. Celui-ci utilise peu les registres. Or, les instructions SSE disposent de 8 registres 128 bits contre 8 registres 64 bits pour 3DNow ! Avec le SSE, on peut alors envisager de stocker une matrice 4x4, très utile en 3D, et conserver l'autre moitié des registres disponibles pour faire passer les vecteurs à multiplier par la matrice. Ceci est impossible avec le 3DNow! et imposera de nombreux transferts en mémoire. De plus, le 3DNow! bloque l'unité FPU classique contrairement au SSE. Peut-être qu'un jour j'écrirai un article sur l'utilisation en conditions réelles des instructions SIMD :)))
VI. Kylix▲
Si l'assembleur intégré de Kylix supporte lui aussi les nouveaux jeux d'instructions SIMD, il n'existe par contre pas de gestionnaire de mémoire adapté aux instructions SSE et SSE2. Seules les instructions 3DNow! pourront être utilisées sous Linux.
Conclusion▲
Nous avons vu dans cet article comment utiliser les instructions 3DNow!, SSE et SSE2. Leur mise en œuvre est simplifiée par l'assembleur de Delphi 6 qui reconnaît les mnémotechniques correspondantes. Les gains en performances sont surtout intéressants pour le SSE et le SSE2.
Code source (13 ko, y compris le gestionnaire de mémoire)